


Keras之小众需求:自定义优化器

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
今天我们来看一个小众需求:自定义优化器。
细想之下,不管用什么框架,自定义优化器这个需求可谓真的是小众中的小众。一般而言,对于大多数任务我们都可以无脑地直接上 Adam,而调参炼丹高手一般会用 SGD 来调出更好的效果,换言之不管是高手新手,都很少会有自定义优化器的需求。
那这篇文章还有什么价值呢?有些场景下会有一点点作用。比如通过学习 Keras 中的优化器写法,你可以对梯度下降等算法有进一步的认识,你还可以顺带看到 Keras 的源码是多么简洁优雅。
此外,有时候我们可以通过自定义优化器来实现自己的一些功能,比如给一些简单的模型(例如 Word2Vec)重写优化器(直接写死梯度,而不是用自动求导),可以使得算法更快;自定义优化器还可以实现诸如“软 batch”的功能。
我们首先来看 Keras 中自带优化器的代码,位于:
https://github.com/keras-team/keras/blob/master/keras/optimizers.py
简单起见,我们可以先挑 SGD 来看。当然,Keras 中的 SGD 算法已经把 momentum、nesterov、decay 等整合进去了,这使用起来方便,但不利于学习。所以我稍微简化了一下,给出一个纯粹的 SGD 算法的例子:?
应该不是解释了吧?有没有特别简单的感觉?定义一个优化器也不是特别高大上的事情。
现在来实现一个稍微复杂一点的功能,就是所谓的“软 batch”,不过我不大清楚是不是就叫这个名字,姑且先这样叫着吧。大概的场景是:假如模型比较庞大,自己的显卡最多也就能跑 batch size=16,但我又想起到 batch size=64 的效果,那可以怎么办呢?
一种可以考虑的方案是,每次算 batch size=16,然后把梯度缓存起来,4 个 batch 后才更新参数。也就是说,每个小 batch 都算梯度,但每 4 个 batch 才更新一次参数。?
应该也很容易理解吧。如果带有动量的情况,写起来复杂一点,但也是一样的。重点就是引入多一个变量来储存累积梯度,然后引入 cond 来控制是否更新,原来优化器要做的事情,都要在 cond 为 True 的情况下才做(梯度改为累积起来的梯度)。对比原始的 SGD,改动并不大。
上面实现优化器的方案是标准的,也就是按 Keras 的设计规范来做的,所以做起来很轻松。然而我曾经想要实现的一个优化器,却不能用这种方式来实现,经过阅读源码,得到了一种“侵入式”的写法,这种写法类似“外挂”的形式,可以实现我需要的功能,但不是标准的写法,在此也跟大家分享一下。
原始需求来源于之前的文章从动力学角度看优化算法SGD:一些小启示,里边指出梯度下降优化器可以看成是微分方程组的欧拉解法,进一步可以联想到,微分方程组有很多比欧拉解法更高级的解法呀,能不能用到深度学习中?比如稍微高级一点的有“Heun 方法 [1]”:
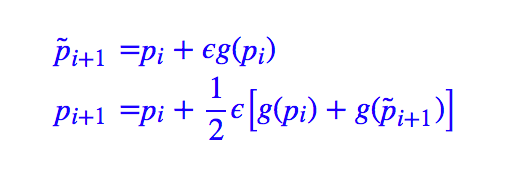
其中 p 是参数(向量),g 是梯度,pi 表示 p 的第 i 次迭代时的结果。这个算法需要走两步,大概意思就是普通的梯度下降先走一步(探路),然后根据探路的结果取平均,得到更精准的步伐,等价地可以改写为:
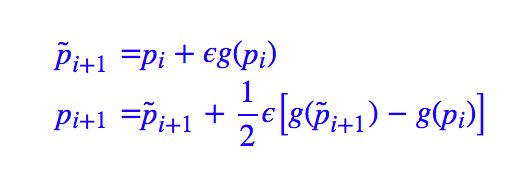
这样就清楚显示出后面这一步实际上是对梯度下降的微调。?
但是实现这类算法却有个难题,要计算两次梯度,一次对参数 g(pi),另一次对参数 p?i+1。而前面的优化器定义中 get_updates 这个方法却只能执行一步(对应到 tf 框架中,就是执行一步 sess.run,熟悉 tf 的朋友知道单单执行一步 sess.run 很难实现这个需求),因此实现不了这种算法。
经过研究 Keras 模型的训练源码,我发现可以这样写:
用法是:
其中关键思想在代码中已经注释了,主要是 Keras 的优化器最终都会被包装为一个 train_function,所以我们只需要参照 Keras 的源码设计好 train_function,并在其中插入我们自己的操作。在这个过程中,需要留意到 K.function 所定义的操作相当于一次 sess.run 就行了。
注:类似地还可以实现 RK23、RK45 等算法。遗憾的是,这种优化器缺很容易过拟合,也就是很容易将训练集的 loss 降到很低,但是验证集的 loss 和准确率都很差。
本文讲了一个非常非常小众的需求:自定义优化器,介绍了一般情况下 Keras 优化器的写法,以及一种“侵入式”的写法。如果真有这么个特殊需求,可以参考使用。
通过 Keras 中优化器的分析研究,我们进一步可以观察到 Keras 整体代码实在是非常简洁优雅,难以挑剔。
[1].?https://en.wikipedia.org/wiki/Heun%27s_method
点击以下标题查看作者其他文章:?
 #投 稿 通 道#
#投 稿 通 道#
?让你的论文被更多人看到?
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢??答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。?
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。


