


分布式查询优化器的经典文章有哪些?
分布式查询优化器相关的经典理论或者论文有哪些?
近期看到过如下比较不错的论文,求再能推荐一些经典的文章?
The MemSQL Query Optimizer: A modern optimizer for real-time analytics in a distributed database
Query Optimization in Microsoft SQL Server PDW
Incorporating Partitioning and Parallel Plans into the SCOPE Optimizer
F1 Query: Declarative Querying at Scale
Orca: A Modular Query Optimizer Architecture for Big Data
Continuous Cloud-ScaleQuery Optimization and Processing,这篇是对SCOPE的优化,正在看,还没看完。有一些查询优化相关的经典论文, 不过不是分布式的,也可以看看,新研究这个领域菜鸟一枚,求共同学习~~
TheVolcanoOptimizerGenerator
CascadesFrameworkForQueryOptimization
Eddies Continuously Adaptive Query Processing
Robust Query Processing through Progressive Optimization
- hyper团队的大佬开设的课程:Query Optimization。
- Efficiency in the Columbia Database Query Optimizer,一篇博士论文,cmu的peloton中的查询优化器就是照这个论文写的。
原文链接:
ORCA优化器浅析大家好,我是 「微扰理论」。目前在 hashdata 担任数据库内核研发工程师,感兴趣的同学可以通过文末联系方式找我内推哦。入职即享20天年假,优秀更可远程办公,海量HC等你来投。感兴趣也可以通过之前的文章「如何心算多位数乘法」了解我组日常沟通氛围。 微扰酱也是极客时间专栏 《业务开发算法50讲》 的作者;欢迎大家关注。
微扰酱最近因为工作需要,学习了一下 ORCA 的论文 《Orca: A Modular Query Optimizer Architecture for Big Data》,这里记录一下学习笔记;重点将会放在 ORCA 的优化过程上,这也是最近工作中最需要了解的部分。
ORCA 是 Pivotal 开源的一款基于 Cascades 框架的数据库优化器,当时也应该是世界上唯一一个开源的、与数据库主体独立的、可服务于多个不同数据库产品的查询优化器。项目应该是11年就开始开发,论文则是在16年正式发布,至今已经走过了10个年头。
当然,所谓服务多个不同数据库产品,其实到目前为止也只是支持了 Pivotal 公司旗下的 HAWQ 和 Greenplum 两个产品而已,如果需要支持其他数据库,则需要针对算子、元数据等差异进行适配,工作量也相当不小。据我所知,似乎没有什么公司基于 ORCA 实现了其他数据库的优化器。
而目前,Greenplum 自身的很多查询也需要 fallback 到 pg 的优化器才能生成查询计划,在 GPDB 内核升级了若干个版本之后,ORCA 在功能上来说已经不够完备,社区活跃相比于刚开发的时候有所下降。不过 ORCA 依旧是 Cascades 架构的一个非常优秀的开源实现,被工业界广泛参考,值得对优化器感兴趣的同学好好学习一下。
站在巨人的肩膀上,ORCA 在一开始设计的时候,就考虑的比较充分,提供了以下一些特性:
- 模块化: ORCA 和之前的优化器实现都所有不同,开发伊始就是一个独立的模块;定义了数据交换的方式和接口,使得 ORCA 服务于不同的数据库产品成为可能。
- 扩展性: ORCA 对表达式、优化规则的抽象非常清晰;在上面添加规则应该比较容易。
- 多核支持:ORCA 将优化器任务抽象为多个 job,并实现了 scheduler 进行调度,因此可以利用多核并发提高查询优化效率。
- 可验证性: ORCA 提供了一系列对优化器验证和测试的工具。
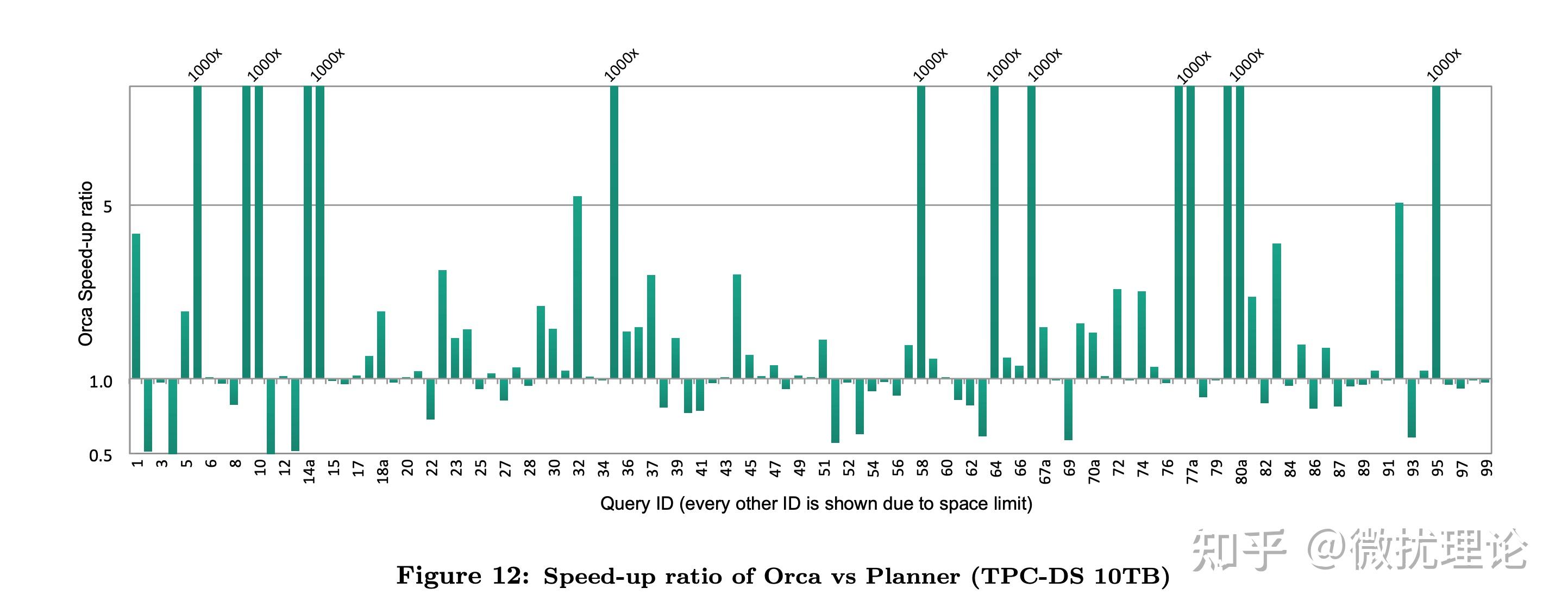
最终,ORCA 带着 Cascades 框架与生俱来的优势,在 Pivotal 当时的系统上获得了非常显著的性能提升。
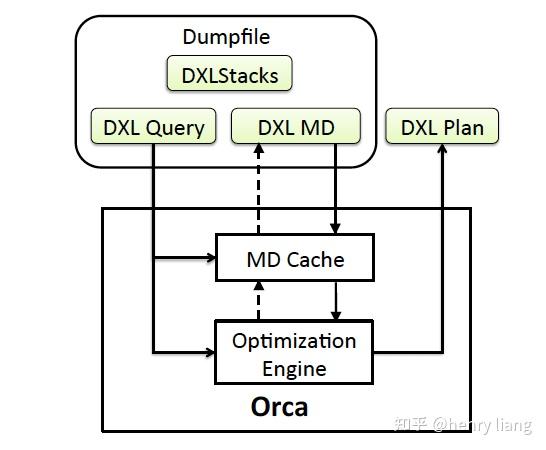
我们前面提到,在 ORCA 以前,几乎所有的优化器都是和数据库系统耦合在一起的;而 ORCA 希望能适配更多的数据库,自然首先要对和数据库系统交互的接口进行抽象和设计。
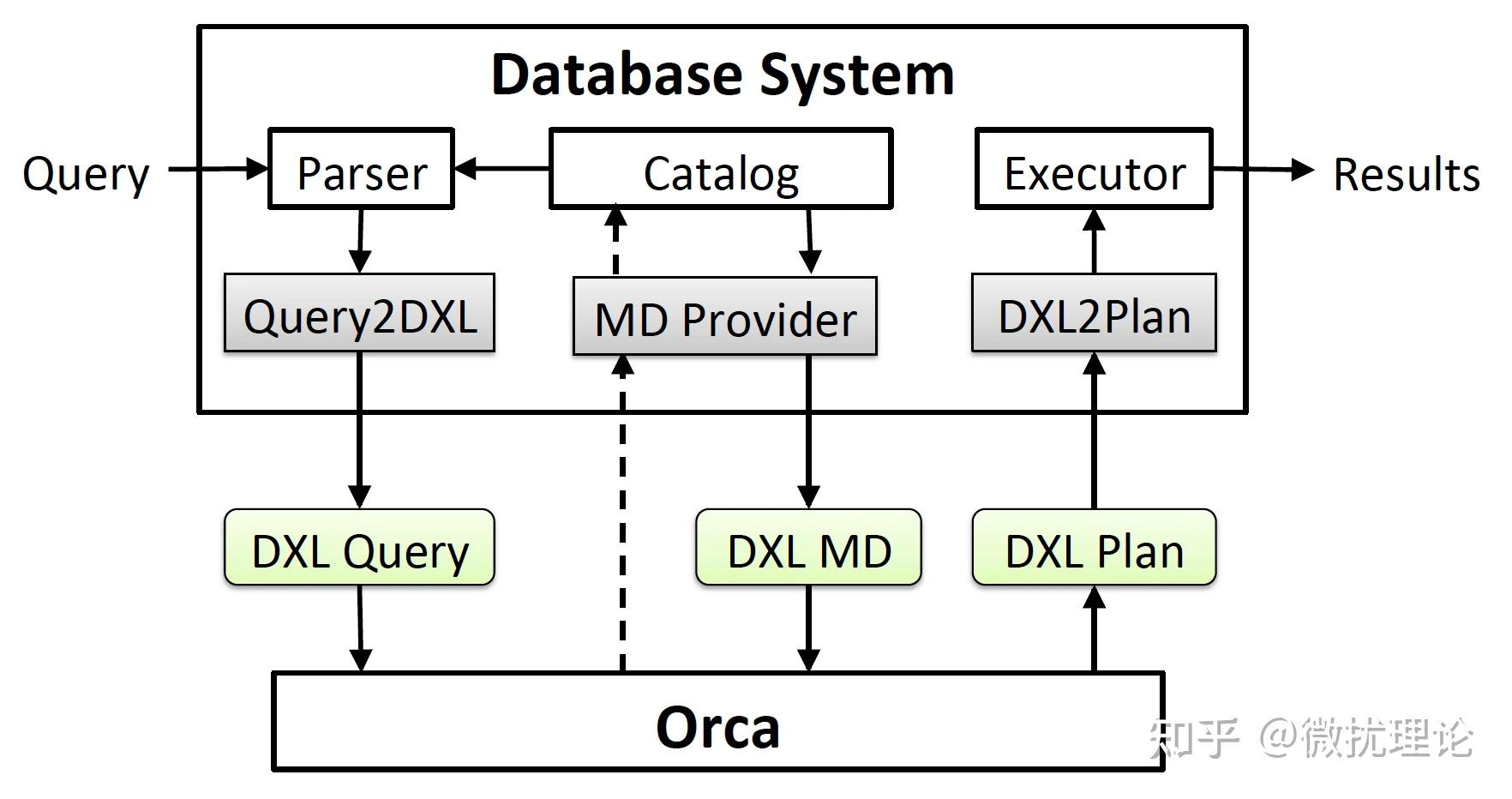
DXL 正是为了这一目标而设计的,通过定义了一系列基于XML语言的语法,ORCA 可以通过接口获得查询树和源数据的相关信息,也可以将优化好的查询计划通过接口提供给数据库系统进行执行。不同的数据库原则上只需要提供对 Query2DXL\\MD Provider\\DXL2Plan 这几个模块的适配和实现即可让 ORCA 成为该数据库的优化器了,所有的信息都会通过 DXL 的方式进行交互。
这也天然得让 ORCA 的测试变得简单,其独立部署的特性,让我们只需要提供文本格式的 DXL 文件,就可以模拟查询语句的输入,而无需启动整个数据库系统。校验的时候则只需要比对输出的 DXL 计划是否符合预期即可。
ORCA 论文中将架构分为了6个部分,分别是 Memo, Seach and Job Scheduler, Transformation, Property Enforcement, Metadata Cache 和 GPOS。
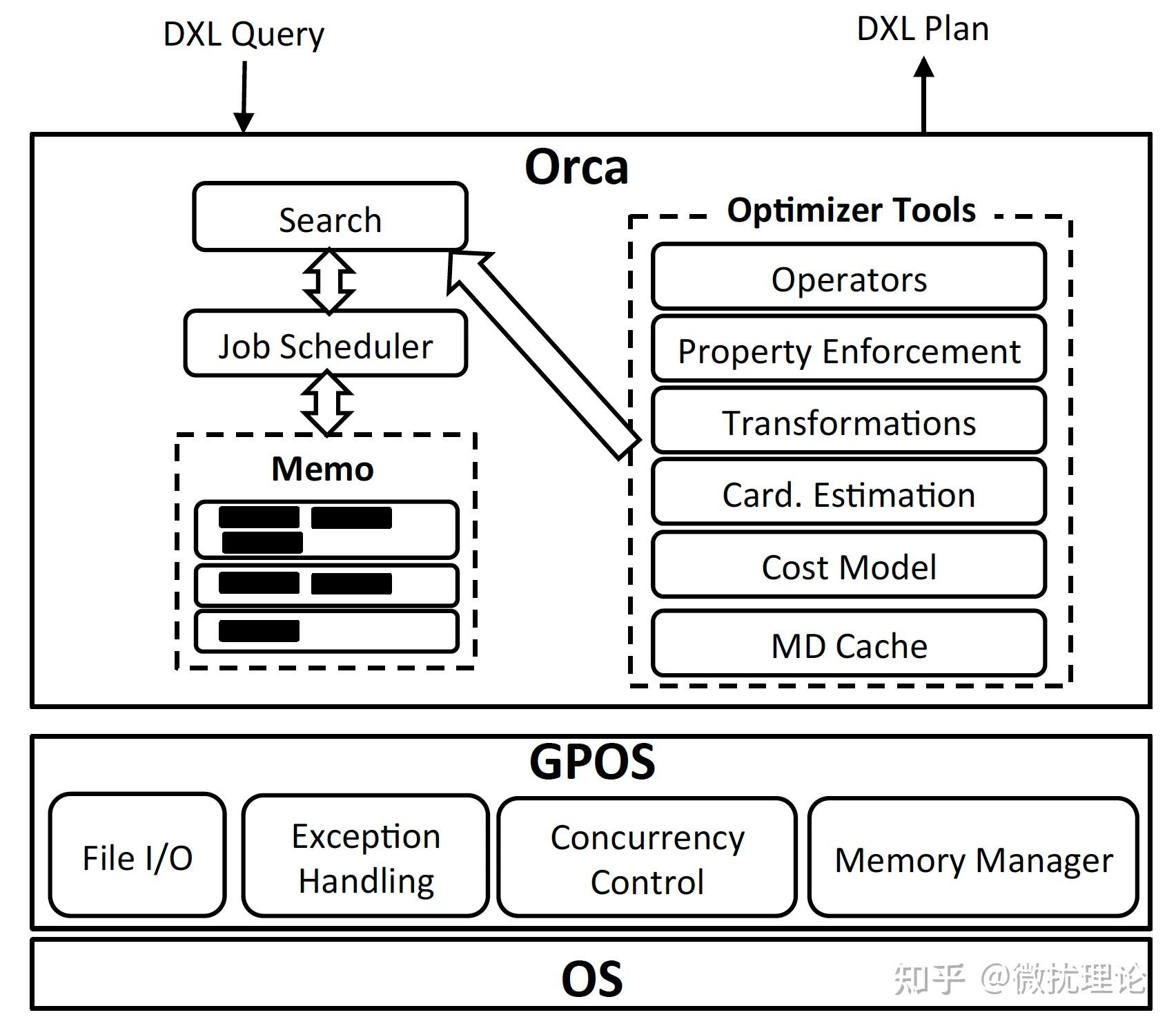
对于这样的架构划分微扰酱其实是觉得有点奇怪的,比如 Search 和 Transformation 在我看来就不是边界清晰的独立部分;不过我们还是按照原作的意思简单阐述一下。
其中,GPOS 是为了适配不同操作系统的抽象层, Metadata Cache 则是由于元数据变动不频繁特性所引入的缓存层;比较独立,和优化过程关系不大,就不展开讨论了。
Memo,是 ORCA 中用于表示执行计划搜索空间的数据结构,应该是 Cascades 架构的核心所在;和 pg 传统采用的优化器自底向上动态规划寻找最优解的方式不同, Cascades 架构则采用了类似于自顶向下记忆化搜索的策略,相比于自底向上的方式也可以更有效的进行减枝从而在有限的时间里获得更优的方案。 Memo 将整个执行计划搜索空间表示为一系列 Group; 每个 Group 则由执行计划中的一组逻辑上等同的算子表达式构成,在搜索的过程中,新的 Group 可能会被创建,新的算子表达式也可能被添加到 Group 中;我们在讲解优化过程的时候将展开讨论。
Seach and Job Scheduler,本质上描述的是 ORCA 搜索最优计划的过程。如前文所述, ORCA 设计了一个非常不错的调度器,在有依赖关系的计划中,进行并行的搜索工作。整个搜索的过程则由几个部分构成,分别是 exploration\\implementation\\optimization 。其中 exploration 负责根据优化规则补全逻辑上等价的算子表达式,比如 a join b 和 b join a 就是等价的。 而 implementation 则是负责将逻辑算子转化为物理算子,比如 a join b 在物理上既可以是 hashjoin 也可以是 nested loop join 还可以是 merge join。 最后一步则是 optimization, 会将数据属性要求(排序和分布)通过增加算子的方式加到计划上并进行最后的代价估计。
Transformation,其实就是 Search 过程中 exploration 和 implementation 的主要逻辑,基于优化规则对搜索空间进行补全。这里的优化规则,就是指的 Transformation,如 InnerJoin(A, B) -> InnerJoin(B, A) 或者 Join(A, B) -> HashJoin(A, B) 等。
Property Enforcement,则就是前面说的 optimization 里的一步。 在我们的查询语句或者执行计划的节点中可能会要求数据按照某种方式分布,或者按照某些字段排序;这些要求,就是 Property,我们不时需要添加一些算子,去使得数据按照要求的属性排布。这一步显然需要在最后的代价估算之前完成。
现在我们来聊一聊大部分读者最关心的部分, ORCA 优化 SQL 语句的具体步骤;后续讲解都将基于下述例子展开。
SELECT T1.a From T1, T2
WHERE T1.a=T2.b
ORDER By T1.a;
我们知道任何一条语句首先当然是传递给数据库系统的;在 ORCA 中,我们会复用数据库(Greenplum)对语句的解析能力,而要求数据库系统讲解析树以 DXL 的格式传递给 ORCA;因此我们也就得到了可以认为是未被优化的 SQL 语句逻辑表达式和 copy-in 初始化的 Memo 结构体,显然也是一个树状的结构。
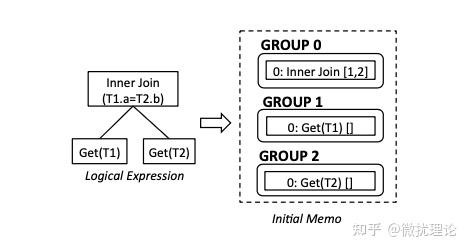
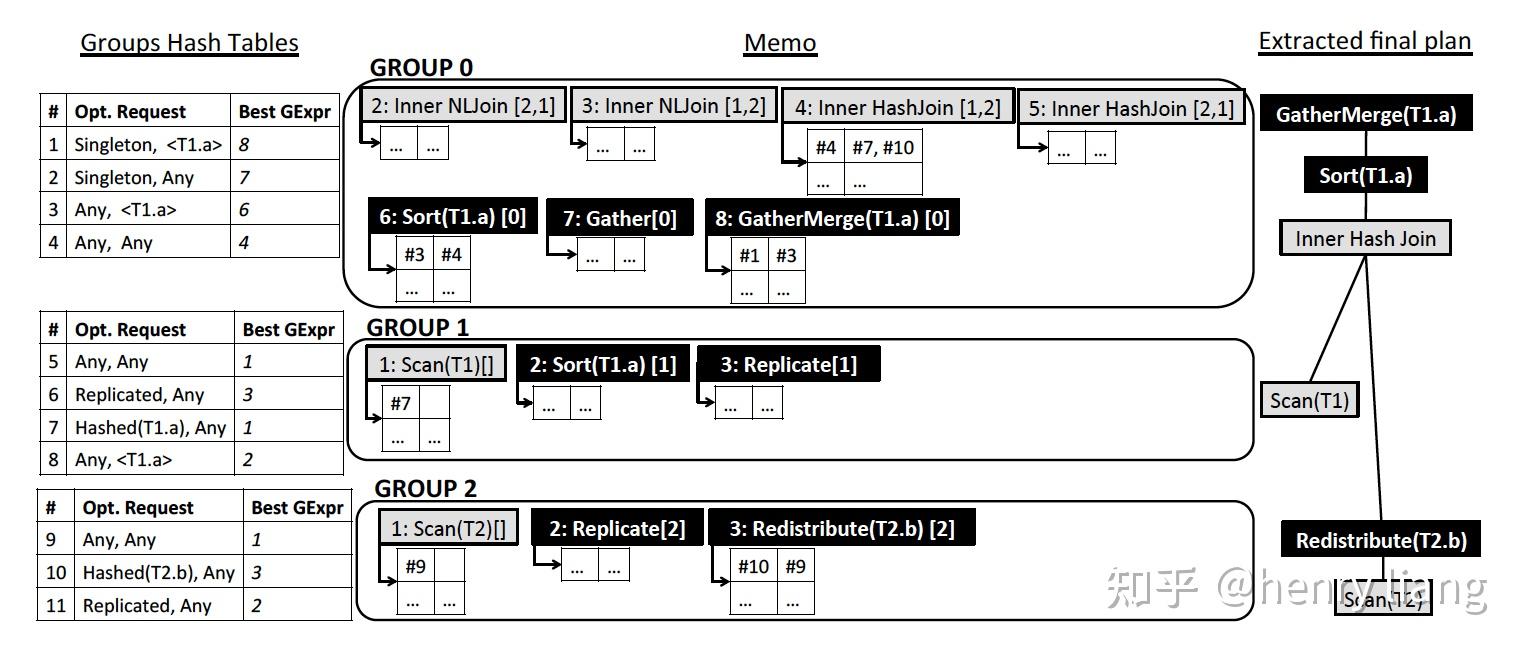
例子中SQL语句所对应的逻辑表达式和初始化的 Memo 如图所示;其中 Group 之间的依赖关系是通过算子间的引用关系所描述的。在例子中, Group 0 中的 InnerJoin[1,2]就代表着 Group 1 和 Group 2 是 Group 0 的子表达式。
在 Memo 被初始化完毕之后,我们就会马上开始优化的过程,具体来说包含以下四个步骤:Exploration\\Statistics Derivation\\Implementation\\Optimization;我们逐一讲解。
其实这一步前面已经简单提过,就是对逻辑等价的算子的扩展,目的是补全搜索空间;这一步完成后,意味着 Memo 应该存储着指定 SQL 语句所对应的完整逻辑搜索空间。而具体的过程,就是对每一个 Group 的表达式进行规则的匹配和应用,以添加新的表达式到某个 Group 或者创建新的 Group。 比如前面说的 InnerJoin[1,2]-> InnerJoin[2,1] 就对应着规则 CXformJoinCommutativity。
我们知道,对算子估计代价的时候,我们需要知道一些表的数据分布情况,比如每个表有多少行数据,对于某一列来说不同的值又有多少行数据等等。这些信息,通常采用对表进行数据直方图的统计来估计,目的是为了估算基数和数据倾斜。这一步骤则正是在优化的过程中,为 Memo 中的 statistics object 绑定上合适的估计值,以便于之后估计最终的执行代价;显然,在这个步骤中不会导致 Memo 搜索空间的变化。
整个获取统计信息的过程比微扰酱想象中的要复杂一些,分为自顶向下和自底向上两个阶段。
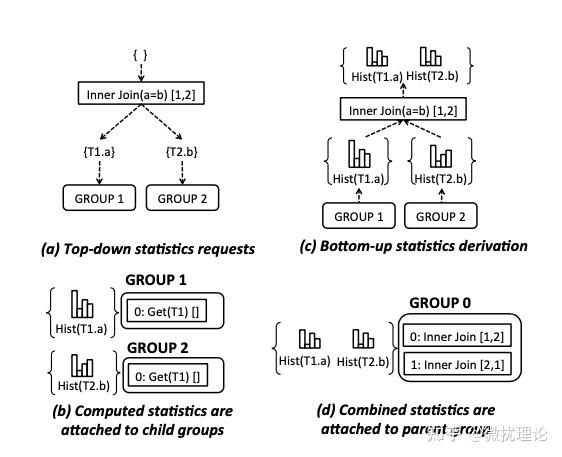
首先,我们会从根节点往下分发信息统计的请求,直到叶子节点。每个 Group 会且仅会存在一个 statics object。而计算统计信息的时候,其实同一个 Group 下的不同表达式估计出来的结果很可能是不同的;以 InnerJoin 为例,在有多个不同的 Join 顺序时,带有更少的 Join 条件的表达式比带有更多的 Join 条件的表达式的直方图信息会更靠谱一些,我们每次求解某个 Group 的统计信息时,都会选择最靠谱的算子进行估计。然后,当子节点的统计信息绑定完成之后,父节点就会组合子节点的统计信息并绑定到父节点的 Group 中,直至自底向上完成所有节点统计信息的绑定。
理解了 Exploration 的过程之后,Implementation 的过程就很好理解了,本质上都是对 Transformation 的应用。两者主要的区别在于这次我们触发和应用的规则都是用于创建物理执行算子的。 比如 CXformInnerJoin2NLJoin 和 CXformInnerJoin2HashJoin 被触发时就会产生 Hash Join 和 Nested Loop Join 的物理算子。
最后一步,则是优化了。事实上,在以上三步里,ORCA 并没有很体现出其 MPP 环境下特有的属性,在这一步里则终于会有所体现。 如前文所述,一些算子和我们的查询本身都可能会有对数据分布和有序性的要求;比如在本文的例子中,我们就要求最终的数据按照 T1.a 列进行排序,或者对于 HashJoin 这样的算子来说,我们显然会要求在 MPP 环境下,被 Join 的两张表需要按照 Join 的列哈希分布,这样才能保证会被 Join 条件命中的两表中的数据一定都分布在同一台机器上。
这样的要求我们会通过自顶向下传递优化请求的方式在 Memo 中通过添加部分算子的方式得以满足,这一步被称为 Property Enforcement。比如为了满足排序的要求,我们就会添加 Sort 算子;而为了使得数据分布正确,我们可能会引入 Redistribute 算子。 优化请求会不断的往下传递,每次向下传递的优化请求对数据分布和排序的要求会同时取决于算子收到的优化请求,也会取决于当前算子的要求;而这些信息,我们都会在每个 Group 和每个算子表达式中通过哈希表的方式进行维护,这样计算过的结果也不必被重复计算。在算子的哈希表下,算子之间的依赖关系也通过和 Request 的引用关系维护起来了,具体可以看后面的例子。
而在 Group 下的哈希表中,每个请求都会和当前最优的算子表达式绑定。这里所谓的最优是代价模型利用前述统计信息所估计的代价最小,具体过程在论文中没有展开讲解,等微扰酱看懂代码之后可能还会再撰文讨论。
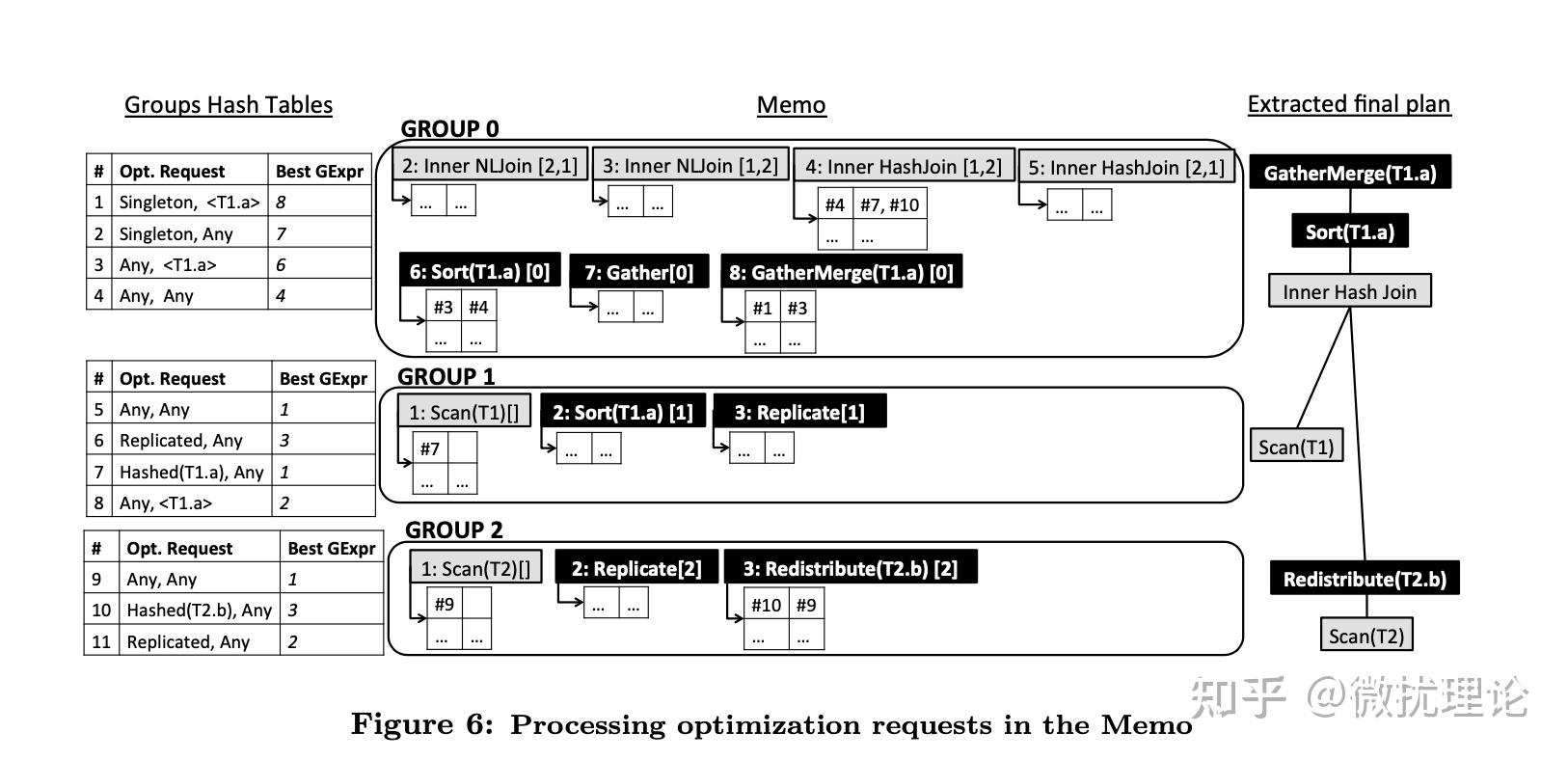
针对前面的例子,论文中实际上给了一个非常具体的示意图,从 Group Hash Table 中的第一个优化请求#1开始,可以依次串联 GExpr 8: GatherMerge -> Request 3 -> GExpr 6: Sort -> Request 4 -> GExpr 4: Inner HashJoin ->{Request 7, Request 10}...,直至描述出完整的最优执行计划。 ORCA 论文对这个例子有非常具体的讲解,迷惑的同学可以对照论文进一步了解。
论文还花费不少笔墨阐述了并行执行优化实现、元数据交换、可验证性和实验等部分;感兴趣的同学可以自行阅读论文了解。
应该是入坑数据库以来第一篇关于数据库内核的文章,虽然只看了论文还未深入代码细节,但写完还是很开心的,希望未来可以更稳定地输出更多和数据库相关的文章;欢迎大家持续关注,不妨点个关注吧。
微扰酱也正在组织各种「残酷的」学习打卡活动,比如 CSAPP 阅读打卡活动就正在火热进行中!想来一起组队刷 coursera 或者 leetcode 的话可以关注公众号;菜单中也有微扰酱的联系方式。
在之前的几片paper笔记中,对最为主流的两套优化器框架进行了解读,包括bottom-up dynamic programming的search策略和基于Top-down memorization的search策略,文章通道:
System-R:
https://zhuanlan.zhihu.com/p/364303913Volcano / Cascades
https://zhuanlan.zhihu.com/p/364619893https://zhuanlan.zhihu.com/p/365085770从上面这3个命名就能看出来,第一套框架是有System-R这个实际的实现系统的,虽然它是IBM research lab中的实验性项目,并没有做到商业化,但从论文的描述中,还是可以清晰的捋出实现脉络,比较简单易懂,易于指导工程实践(目前PolarDB 并行优化器的设计,也参考了DP-based的思路)。
但Volcano/Cascades的论文内容则要抽象和艰深的多,原作者Graefe在paper中提及到Volcano项目也只是一个学术性的原型系统,没有一个著名的系统为其背书(当然,Graefe在2000年前后去了MicrosoftSQL并主导了SQL Server查询优化器的整个重新设计和实现)。相信很多人和我一样,在看完论文甚至一些的导读文章后,也无法很好的将这个框架与工程实现映射起来,而在读完Orca这篇paper,相信可以帮助我们更好的理解cascades这个牛叉的框架。
Orca是Pivotal公司基于Cascades框架自研的一套独立的查询优化器服务,主要服务于Pivotal公司的另外两个系统:基于Hadoop的HAWQ和著名的Greenplum,阿里的大数据分析引擎Hologres也是用Orca作为其优化器。从这里也可以看出,复杂的Cascades框架,确实具有更加的复杂查询处理能力,因此更适合于大数据或数仓类型的产品。其基本特点有4个:
- 模块化,以独立的Service形态单独存在,并不依附于特定的数据库产品,对外是标准化的接口和协议([1]),这样理论上可以被集成到任何数据库系统中。
- 扩展性,可以扩展新的operator/cost model/property/rules
- 支持并行优化,其自身实现了subtask和job scheduler
- 可验证性,实现了方便测试与debug的工具集,便于复现问题 + debug或者test,也便于快速迭代新功能
- 作为一个standalone服务单独存在是Orca比较有趣的一点,其基本流程
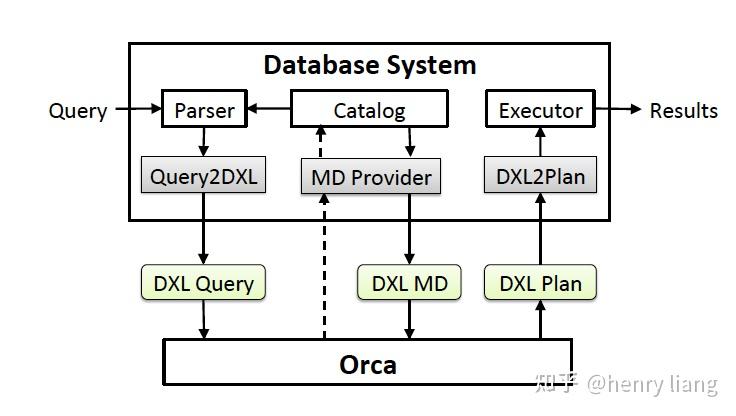
- Query进入DB后,要经过parser转换为AST,然后通过Query2DXL这个模块,将AST描述为DXL可以表述的标准形式(DXL Query)
- Orca接收到query后开始优化,在过程中会获取必要的元信息(如表/列的schema信息,统计信息等),这通过MD Provider实现,并转换为DXL MD传递给Orca,Orca内部是有MD cache的,来避免频繁获取metadata,metadata维护一个version信息,来判断是否过时。
- Orca完成优化流程,确定最优plan后,以DXL Plan的形式,传递给DB端,DB端使用DXL2Plan这个模块转换为内部可识别的physical plan,交由Executor执行。
可以看到Query2DXL,MD Provider,DXL2Plan这3个模块构成了适配层,不同的DB侧只需要根据自身特点完成转换工作即可。但个人感觉这个过程还是有些重,DXL(XML)本身就是复杂而臃肿的协议,query/plan的复杂性、metadata的维护都还是有一定工程挑战的。
Orca的整体框架和各个组件如下
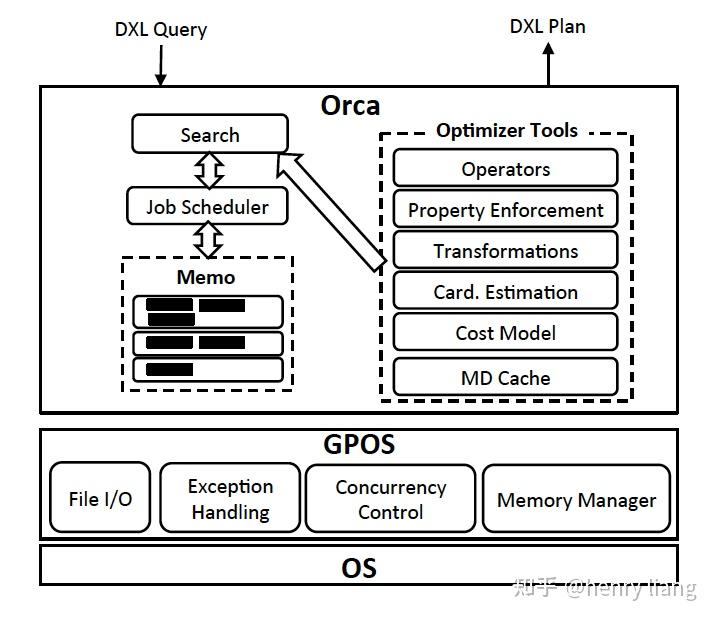
1. Memo : Cascades中的概念,是整个搜索空间的全局容器,代表逻辑等价类Group,表达式 Expr,都包含在其中,内部通过一些机制来实现高效的结构重用,减少内存开销。
2. Search + Job Scheduler,表示具体的算法流程和执行优化的任务调度,和Cascades的paper一样,它把优化任务拆分为subtask。Search的整体过程和Cascades paper中虽然没有完全对齐,但基本思路是一致的:
exploration进行逻辑变换 <-> implementation完成物理算法选择 -> 递归到下层继续优化。
3. Transformation : 这里包括logical + physical的转换,每个rule,都是可以单独开/关的。可以看到,Orca中的transformation,既包含逻辑等价变换,也包含选择物理算子,而它的exploration则是纯粹的等价变换,为了便于区分,我们还是使用exploration来表示逻辑变换,而使用implementation表示选择物理执行算法。
4. Property Enforcement : property的描述是规范且可扩展的,可以具有不同类型,paper中列举了logical property(输出哪些columns),physical property(数据的有序性,分布情况)+ scalar property(join columns,这里猜测是和property有关??)。
这里的property和Cascades中的概念完全一致,在上层算子确定物理执行方式的同时,会对下层产生某种对输入数据的物理属性要求(e.g sort merge join要求数据在join key上有序),下层算子可以自身来保证满足这种物理属性要求(e.g index scan提供有序性)或者利用Enforcer来保证(e.g 加入sorting操作)。
5. Metadata Cache缓存在Orca侧,metadata通过version number来判断是否失效,这样下次再获取meta时可以先验证version信息,如果已过期再获取新数据,避免过多大量信息交互。
paper中使用了一个简单SQL 来示例优化流程:
SELECT T1.a FROM T1, T2
WHERE T1.a=T2.b
ORDER BY T1.a;数据是sharding的,T1 基于Hash(T1.a)分布,T2基于Hash(T2.a)分布。这个plan的初始状态是
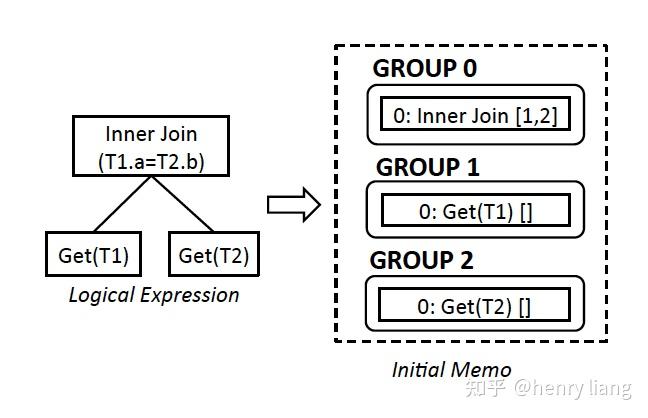
可以看到,自顶向下,每个group描述一个逻辑操作,上层group 0中通过编号1,2引用了下层group。每个group内的编号0,是初始的expr。
1. Exploration:
在group内,基于已有expr做logical transformation,这里可能会生成新的expr,在本例中可以通过join交换律从 Inner join[1,2]=> Inner join[2,1]。如果逻辑变换较大,则可能生成新的group,例如执行view merge操作展开内层表到外层,就会出现作为外层表的多个table group。
从论文中的描述,感觉exploration是集中完成的,而没有和implentation交错执行,估计交错方式实现复杂度太高。
2. Statistics Derivation:
在完成exploration后,就可能建立起由逻辑等价类(group)组成的多棵候选的plan tree。在开始搜索物理plan之前,先要有必要的统计信息才可以计算相关的代价,因此有一个收集+生成统计信息的过程。在Orca中,这个统计信息主要就是指一系列的column histograms,用它来做Cardinality Estimation和检测data skew。
这里针对每个group的statistics,提出了一个非常有趣的概念:[2],Statistics promise。我们都知道统计信息都是不精确的,那么在同一个逻辑表达式上,也许有多个统计信息可以使用,可以尽量选择置信度高的统计信息用于估算。例如一个group中,可能有多个表示inner join的等价group expr,其中1种join组合方式,涉及的join condition较少,而另一种join组合方式的join condition则更多(不同join order),这时选择更少condition的可能误差就会更少(cardinality estimation的误差会随着乘积传播和扩大)。
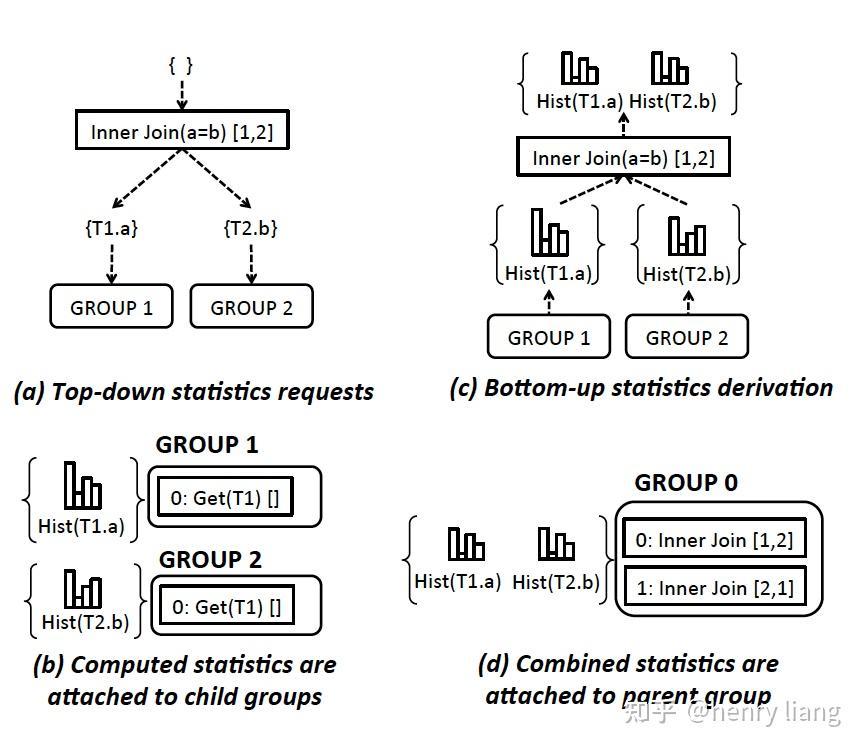
对各个group,自底向上完成,histogram的估算有很多方法,例如SQL Server中的方法:
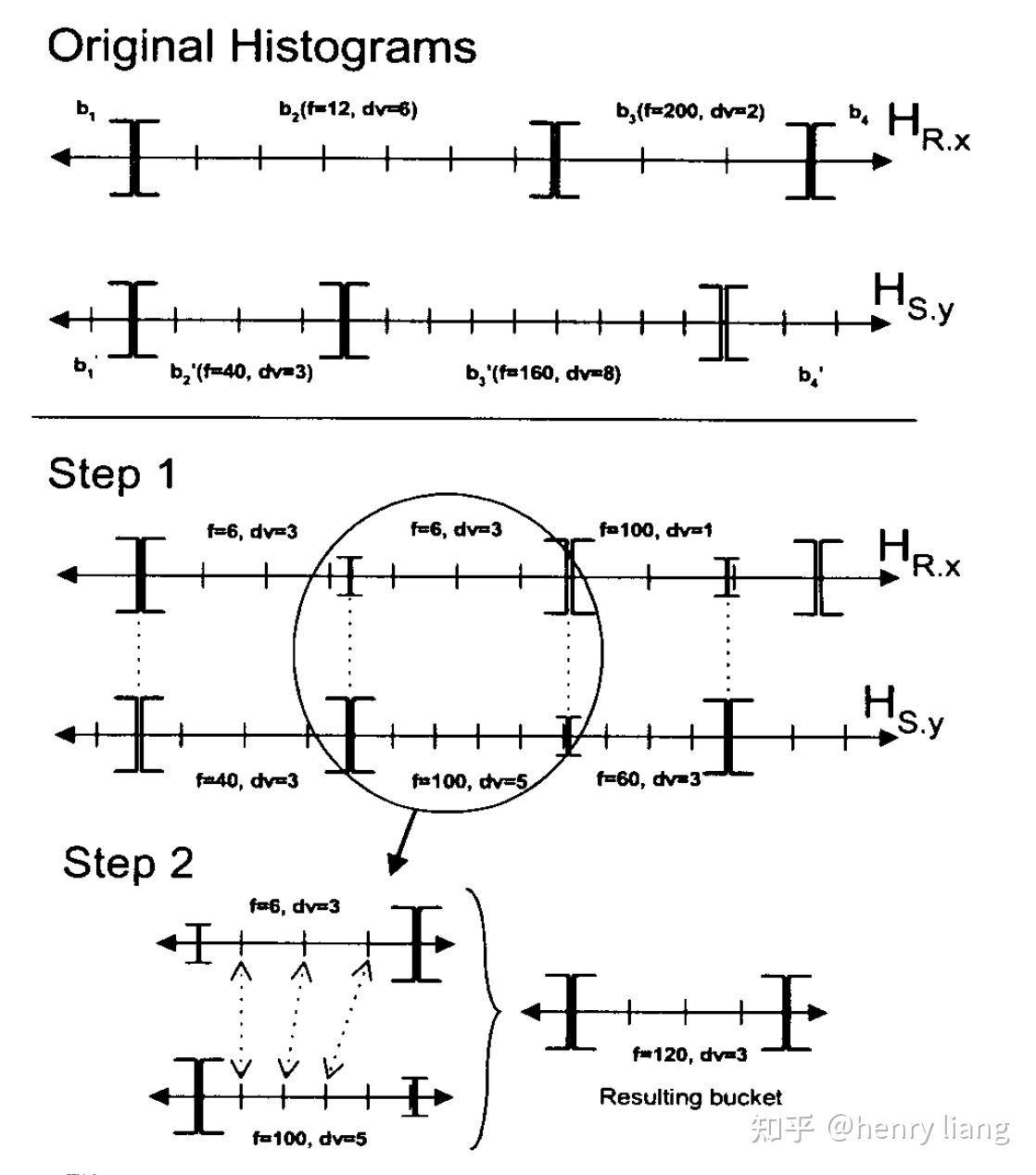
上图并不难理解,根据join两侧的column histogram,获取两个domain中的bucket boundaries集合,等于将两个histogram都切分成了更小的sub bucket,在每个sub bucket内仍假设均匀分布,并基于join inclusion的假设来计算join cardinality,再累计起来,就得到了join group expr的histogram。
3. Implementation:
为每个logical group expr,选择所有可能使用的物理实现算法,包括scan方式,join算法等,生成对应的physical group expr。
4. Optimization:
Search plan space,过程中会计算相应cost。初始会从root group开始,根据一个optimization goal(cost limit , property requirement),对一个group开始优化,等同于从这个group开始,选出其内部最优的physical expr以及其下层整个physical expr tree。
在一个group内,会从每个step 3生成的每个physical expr为起点深度优先,向下查找,首先会扣除它自身的cost,并根据其上层的property requirement以及expr自身的property特性,形成对其输入group的physical property要求,这样就从当前level 1 的(cost , prop requirement1) 递归到了下层group (level 2),optimization goal变为了 (cost - l1 cost, prop requirement2)。
对每个physical expr来说,如果所属group的optimization goal中的property requirement可以被expr本身输出的物理属性所满足,则可以直接应用该expr,否则需要加入enforcer来强制目标属性,下图中给出了一个简单的inner hash join的优化过程:
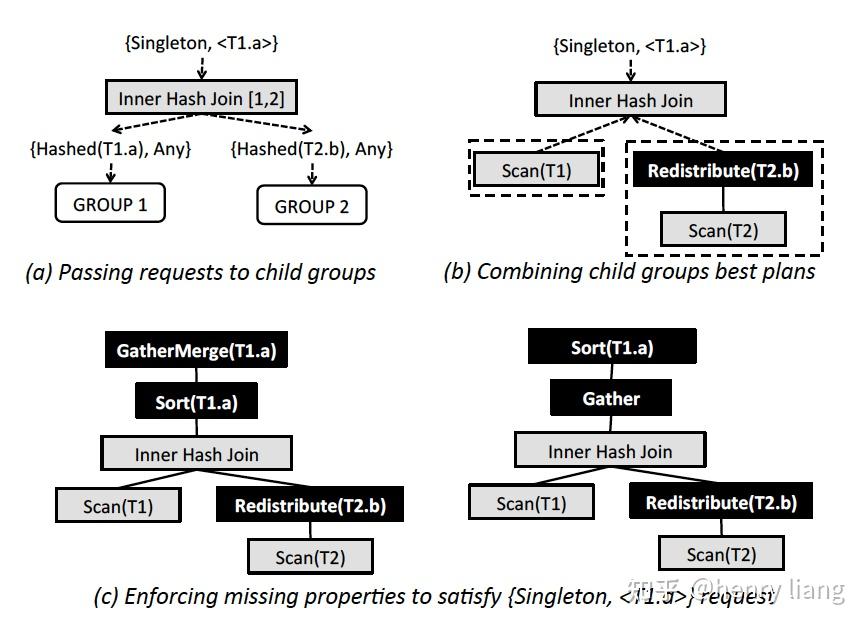
图(a)中,初始的optimization goal施加在group 0上,它要求输出数据在单个节点中(singleton),且按照T1.a有序。当进入group内处理每个physical expr时(本图中是Inner hash join[1,2]这个expr),会结合inner hash join的特点,生成对children group的optimization goal,这里分别是左右child的 Hash(join key), 顺序则是Any,也就是说,要求左右table数据都分布在join key上,且由于hash join不保序,因此其children也不要求输出有序。
图(b)中,假设T1的数据已经在T1.a列上分布,而T2的分布键却不是T2.b,因此无法满足Hash(T2.b)这个物理属性,需要加入Redistribution(T2.b)这个enforcer来满足分布要求。
图(c,d)中,inner hash join已经在各个节点上完成了co-located join,但数据并不满足singleton的要求,也不满足有序的要求,这时需要加入新的enforcer,那么有两种选择:
要么如图c中,先在各节点排序后在汇总到leader节点,即sort -> gather -> mergesort。
要么如图d中,先gather到leader节点,再对全量数据排序。
选哪种方案,就取决于cardinality 和 cost了。
5. Memo
Memo中高效的组织了Group、Group Expr的信息,使其可以被复用,具体来说
每个group维护一个hash table,保存{property request -> 本group最优physical group expr}的映射。
每个group expr维护一个local hash table,保存(property request -> 各个input的property request)的映射。
上图中是一个比较完整的Memo结构,其中灰色方框的是physical group expr,黑色方框则是enforcer。每个group左侧的table就是 request -> best expr,每个expr下方的小表格,则是property request(表格第一列) -> input children(表格第二列)。
这样首先同一个expr/enforcer,可以以编号的形式被多个其他expr引用,从而实现了结构的复用最小化内存占用。如果想要获取最优expr tree,只需要顺着root group request -> group hash -> group内最优expr -> expr local hash -> children group request -> ...的方式,串连起整个expr/enforcer tree。
6. Metadata exchange
MD 获取的设计提前其作为外挂优化器的灵活性:

不同的外部系统,都可以基于MD Provider提供适配的元数据,元数据会在优化期间保存在MD Cache中,优化结束后可以释放,有个有趣的地方是最左侧的File based Provider,也就是说Orca可以完全不依赖于一个在线系统,这种用local file来mock一个DB的方式,使得Orca可以被更好的测试、调试和验证。
7. 可验证性
优化器可以说是数据库系统中最为复杂和不确定性的组件,在漫长的开发流程中,高效的验证能力,快速发现regression,快速定位问题是保证开发效率以及解决线上问题的必要条件。因此围绕Orca,引入了两个工具:
- AMPERe
当Orca的执行中出现错误,或选中了次优计划时,可以将能够复现问题的最小化环境dump下来,包括query + metadata + config + stack backtrace等,并序列化为DXL的形式,这样后续可以脱离线上系统,以本地DXL文件的形式重新导入Orca,重建问题环境来调试。这和core dump的思路类似。
- TAQO
用来针对optimizer中的cost model进行测试,来衡量一个optimizer对于最优计划的选择能力。其思路其实很简单直接,优化器的本质就是根据计算出的cost,作为执行时间的衡量标准来对alternative plans进行排序,理想情况下最低cost对应的就是最优plan,因此其是否精确,可以用optimizer对于plan的正确排序能力来衡量。
当评估一个cost model时,我们可以从Memo的plan space中,选出若干候选plan(如下图p1 p2 p3 p4) ,观察其cost评估值c与其实际的执行时间a,这样就形成了一对序列(c1, c2 ... cn) + (a1, a2 ... an)。如果是完美的优化器,应该是c序列的顺序,与a序列的顺序完全一致,也就是说cost的顺序就是实际的执行时间顺序,基于这个原则,我们可以用2个序列的顺序相关性,来对目标cost model进行打分,选择相关度最高的cost model。
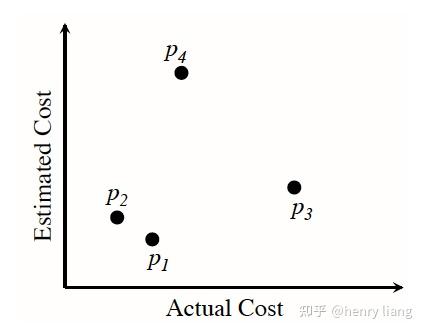
这个测试机制的强大之处在于,它可以不用调整optimizer的细节,基本把它当做黑盒,不绑定在特定的host系统,也不需要做复杂的profiling,易于实现。如果有同学需要评估自己优化器的代价模型,这是个很值得参考的方案。当然还有一些细节,Pivotal也专门写了篇paper介绍TAQO,我在
https://zhuanlan.zhihu.com/p/365621518中做了详细介绍。
相信看完这篇文章,大家能对Cascades框架有更直观的体感。其高度的灵活性和扩展性使其可以更好的扩展search space,更可能选中最优plan,但也导致了search成本更高,时间更长。orca本身也在做一种multi-stage的优化方式,每个stage有cost + 优化时间 + rule subset的限制,在资源不多或要求不高的情况下,就可以得到一个不错的plan。这和SQL Server的思路大致相同。
大概用了9个月的时间,研读了优化器、执行器经典论文,论文主要来源于梁辰:优化器论文列表和https://15721.courses.cs.cmu.edu,辅助性来自一些国外明显的topic。研读期间,学习了
梁辰、https://loopjump.com/对优化器、执行器的论文解读,收益很大。
同时,在研读论文过程中,收集整理了论文的发表单位,以及论文的落地产品。个人理解,论文更多的是体现出一个idea以及这个idea的实现思路,如果想融汇贯通、运用自如,还是需要进一步研究分析相关的开源数据库源码、闭源数据库的功能特性。
由于个人能力有限,对论文的解读、按数据库进行整理的内容可能存在一定偏差或错误,期待能够和感兴趣的同学学习交流、共同进步。
[SIGMOD 1979]Access Path Selection in a Relational Database Management System 论文阅读
本文虽然发表于1979年,但在System R这个关系型数据库研究项目中,提出的制定SQL查询计划思想(自下而上+启发式+基于代价评估)至今仍被主流数据库所使用,例如Oracle、DB2、PostgreSQL等。
?本文解决的主要问题是,用于在不了解数据库存储细节的情况下,执行了一个SQL查询,数据库优化器如何将SQL转换为最优的执行路径,即最高效的执行。
[VLDB 06]Cost-based query transformation in Oracle 论文学习
本篇论文虽是2006年发表,但其中的启发式规则、代价评估规则仍被主流数据库使用。在Heuristic Transformations转换规则中,Join Elimination、Filter Predicate Move Around、Group Pruning规则必然能获得更加的查询计划,但Subquery Unnesting则需要依赖表中具体的数据行数决定。代价评估规则中,给出了8中转换规则,并结合实例说明如何使用。论文也提出了一个代价评估框架,包括框架的组件、state搜索算法、transformation规则的执行方式以及框架的性能优化方法。
[VLDB 2017]Adaptive Statistics In Oracle 12c --学习笔记
论文介绍了查询执行过程中,中间结果统计信息错误导致的问题,并给出了Oracle 12c的解决方案。该解决方案包括使用表的数据和通过自动创建辅助统计信息来验证已生成的统计信息的准确性。
[SIGMOD 2004]Parallel SQL Execution in Oracle 10g --学习笔记
论文介绍了Oracle10g在并行执行方面的新架构和优化。自Oracle7开始,Oracle就基于share-disk架构实现了sql并行执行框架。在Oracle10g对并行执行引擎进行了重构,通过使用全局并行计划模型,使得并行执行引擎更高效、更易于动态扩展、更易于管理。论文不是很好理解,有些内容只是简单的说了下what,没有解释how,另外也涉及到了许多Oracle的相关名词术语。
[VLDB 2015]Query Optimization in Oracle 12c Database In-Memory--学习笔记
Oracle 12c内存数据库是业界第一个 dual-format(同时支持行存、列存)的数据库。在IO层,仍然使用行存格式。在内存中,同时支持行存和列存。数据存储方式的变化,使得数据查询处理算法也要进行扩展,这就要求查询优化器同步做扩展和适配,以便在支持列存的存储、查询计算的情况下,能够产生最佳的查询计划。论文给出了引入Database In-Memory后,查询优化器的扩展,具体包括统: statistics, cost model, query transformation, access path 和 join 优化, parallelism, 以及 cluster-awareness优化。
[VLDB 2013]Adaptive and Big Data Scale Parallel Execution in Oracle--学习笔记
论文介绍了Oracle数据库在执行join、groupby、窗口函数方面引入的新的并行+自适应方法。这套技术的创新点是采用了多阶段并发模型(multi-stage parallelization models),能够在运行时根据实时统计信息,将由于优化器统计信息不准导致的次优plan,动态调整为更优的plan,主要策略是:动态扩展并行执行进程的数量,以及调整数据的重分布策略,避免data skew。论文还讨论了Oracle原有的串行化执行的算子(如top-N)的并行化执行的方法,Oracle从这些自适应并行化技术中实现了巨大的性能提高。
[VLDB 2009]Enhanced Subquery Optimizations in Oracle-Oracle去相关子查询论文学习
paper从优化器、执行器两方面提出了子查询优化的方法:
- 优化器:子查询优化方法,包括子查询合并、基于窗口函数的子查询删除、在groupby查询中删除view,目标是删除冗余子查询块,并将子查询转换为更容易优化的形式。
- 执行器:提出了一种并行执行技术,具有普遍适用性和可扩展性,并可以同经历了某些transform的查询共同使用
另外,paper针对antijoin处理null值的问题,提出了一个anntijoin算子的变种Null-Aware Antijoin,用于优化包含可能为null的column的子查询。
[SIGMOD '03]WinMagic Subquery Elimination Using Window Aggregation--DB2去相关子查询论文学习
paper介绍了IBM DB2中利用窗口函数针对agg场景下去相关子查询的方法,该方法虽然有些约束限制,但如果满足的话,还是很高效的。目前,PolarDB MySQL、OceanBase都实现了这个算法。据了解,Oracle也实现了这个算法。
[SIGMOD 2015]Rethinking SIMD Vectorization for In-Memory Databases--学习笔记
论文作者来自哥伦比亚大学和Oracle。论文基于先进的SIMD指令,例如gathers和scatters,提出了一种新的向量化执行引擎,并给出了selection scans、hash tables、partition的向量化实现代码,在这些基础上,实现了sort和join等算子。论文将提出的向量化实现技术与最先进的scalar和vectorized技术进行了对比,通过在Xeon Phi以及主流CPU的实测结果,证实论文提出的技术的高性能。
[IEEE Data engineering Bulletin 1995]The Cascades Framework for Query Optimization论文阅读
本篇论文已经在SQL Server中落地,论文对Volcano Optimizer Generator论文的后续,作者提出了Cascades优化器框架,对Volcano Optimizer Generator在功能、易用性和健壮性方面的实质性改进,主要的不同点在于volcano是先等价替换出所有的逻辑计划,然后计算物理计划。而cascade是没有区分逻辑计划和物理计划,统一处理。
本论文也是抽象化的提出了一种Cascades优化器框架,给出了一些工程化实现的说明。与Volcano优化器相比,Cascades性能更加。因为Volcano采用了穷举方法,在父节点对子节点优化过程中,采用了广度优先算法,先等价替换出所有的逻辑计划,然后计算物理计划。Cascades是没有区分逻辑计划和物理计划,统一处理,采用了类似深度优先的算法。并且使用了指导规则,一些搜索工作是可以避免的,Cascades的搜索策略似乎更好。
[ICDE 2010]Incorporating Partitioning and Parallel Plans into the SCOPE optimizer--学习笔记
在大规模集群中进行大量数据的分析为查询优化带来了新的机会和挑战。这种场景下,使用数据分区是提升性能的关键。然而,数据重分布的代价非常高,因此,在查询计划中,如果可以在算子中最大程度的减少数据重分布操作,那么可以显著的提升性能。在这个存在分区的环境下。查询优化器需要能够利用数据分区的位置、排序、分组等元数据信息,制定更高效的查询计划。
论文讨论的是微软的Cosmos。Cosmos是微软的一个运行在大规模服务器集群上的分布式技术平台,专门用来存储和分析Massive Data,Scope是运行在Cosmos环境下的数据处理工具
- Scope is the Query Language for Cosmos(Scope是在Cosmos平台下运行的Query语言)
- Scope Is Not SQL (Scope像SQL 但不同于SQL)
- Scope的优化器负责生成最优的执行计划
- scope优化器能够利用数据分区信息能够在代价评估中考虑并行计划、串行计划、二者混合的计划,选出最优解
这篇论文虽是基于scope的,但已经在SQL Server中落地。
[SIGMOD '00]Counting, enumerating, and sampling of execution plans in a cost-based query optimizer学习
在对优化器的测试中,一项重要的测试内容是,对比分析优化器选出的plan的执行时间与优化器中其他候选plans的执行时间,进而判断优化器从候选plans中选择较佳的plan的能力,那么问题就来了,如何才能知道优化器中,其他候选plans的执行时间?
这篇论文给出了一个很好的方法,就是在优化器制定query的执行计划过程中,建立好数字和候选plans的对应关系,在SQL语句执行时,用户可以输入数字,指定执行plan。这个技术已经应用到SQL Server的优化器测试验证中了。
由于SQL Server采用了Cascade框架,因此,整个实现是围绕MEMO结构进行的。
[Data Engineering Bulletin '08]Testing SQL Server's Query Optimizer--学习笔记
查询优化本身就很复杂,因此,验证优化器的正确性和有效性是一项非常复杂的工作。正确性是说生成的查询计划对标原sql,能不能保证结果集的正确性;有效性是说,对原sql执行RBO+CBO变换后,得到的执行计划是不是高效的。
这篇论文描述了测试查询优化器时遇到的一些独特问题,概述了验证微软SQL Server的查询优化器的测试技术,给出了优化器测试过程中的成功经验和教训,最后讨论了测试器测试中持续存在的挑战。
论文更多的是从测试工程的角度说明优化器测试问题,以及微软SQL Server是如何测试优化器的,给出的方法相对要宏观一些,或者说更像是一种方向性的指引。很遗憾,可能是出于商业保密的原因,论文并没有公开优化器测试的实现机制。论文[DBTest 2012]Testing the Accuracy of Query Optimizers,给出了优化器测试的数学模型,但没有从系统工程的角度说明如何进行优化器的测试。这两篇论文有很强的互补性,都是很值得学习的。
[Microsoft Research 2000]Parameterized queries and nesting equivalences--SQL Server去相关子查询
本文为解决SQL关联子查询问题,提出了Apply算子,用于描述SQL子查询,并给出了Apply算子向join转换的恒等式,基于这些恒等式,可以实现SQL子查询去关联。Apply算子已经应用到SQL Server7.0。
[SIGMOD '01]Orthogonal Optimization of Subqueries and Aggregation --SQL Server去相关子查询
论文提出了一种小的、独立的Correlation removal和有效处理outer join、group by的源语(rule),通过正交组成丰富的执行计划,高效解决子查询问题。
[SIGMOD 07]Execution strategies for SQL subqueries --SQL Server去相关子查询
本文描述了SQL Server 2005中用于高效计算包含子查询的查询的大量策略。论文从必不可少的先决条件开始,例如子查询的相关性检测和删除。然后确定了一系列基本的子查询执行策略,例如正向查找和反向查找,以及set-based的方法,解释了在SQL Server中实现的子查询的不同执行策略,并将它们与当前的技术状态联系起来。实验评价对论文进行了补充。它量化了不同方法的性能特征,并表明在不同的情况下确实需要不同的执行策略,这使得基于成本的查询优化器对于提升查询性能必不可少。
[SIGMOD 2012]Query optimization in Microsoft SQL Server PDW--学习笔记
PDW QO是paper描述了SQL Server MPP查询优化器的设计与实现,Paralled Data Warehouse产品的查询优化器(PDW QO)。PDW QO是基于SQL Server单机Cascade优化器技术实现的针对分布式查询的CBO优化器。PDW QO在控制节点采用两阶段方式制定DPlan(分布式执行计划):
- 基于单机Cascade优化器架构,使用全局统计信息,产生若干个潜在winner的memo结构
- 根据数据的分布信息,对这些候选plans进行枚举和剪枝,选择最佳,生成分布式的执行计划。并将这个分布式执行计划树转换为DSQL语句(扩展SQL),分发到各计算节点执行。
在控制节点制定分布式执行计划时,会根据数据重分布的操作将整棵查询执行树切割成不同的子树。每个子树对应查询计划的一个阶段,就是GreenPlum中的slice。每个slice都被转换成DSQL语句,在各个计算节点的sql server上执行,互相之间通过网络,发送到远端时要全物化,同时会收集物化的中间结果的统计信息,然后计算节点执行当前slice对应的dsql语句时,会基于这些统计信息重新进行查询优化,可能会有本地更优的计划。
与基于成本的transform相关的一个基本问题是,这些transform是否会导致需要评估的替代方案的组合数量爆炸,以及它们是否会在查询优化的成本和SQL执行的成本之间提供权衡。PDW优化器在这方面有一个非常重要的搜索优化,即timeout机制+从候选plans选取“seed”plans。
SQL Server优化器的timeout机制,不会生成所有可能的plans。在MEMO中基于全局统计信息的可能winner的plans对所考虑的Search space有很大的影响。为了提升PDW查询优化的效率,尽量不穷举所有的备选plans,而是从备选plans中考虑table的数据分布信息以高效配置DMS算子,选择部分"优质plans",即“seed”plans。这个考虑数据分布的方式和interesting order类似,从上到下提出require distribution,从下向上提出provide distribution,进行匹配,不满足增加exchange,这个选种子plans时,尽量选择不需要增加exchange的候选plans。
目前,没有见到CockroachDB(简称CRDB)公开发表的优化器、执行器方面的论文,但其源码或设计文档中,明确告知了优化器执行器依赖的论文,具体如下:
[Microsoft Research 2000]Parameterized queries and nesting equivalences--SQL Server去相关子查询
[SIGMOD '01]Orthogonal Optimization of Subqueries and Aggregation --SQL Server去相关子查询
[SIGMOD 07]Execution strategies for SQL subqueries --SQL Server去相关子查询
此外,去相关子查询中,实现了[VLDB 06]Cost-based query transformation in Oracle 论文学习中提出的规则。
[ACM Trans'97]Outerjoin Simplification and Reordering for Query Optimization--论文学习
论文的主要贡献如下:
- Outerjoin Simplification,不改变join次序,提出了算法A (基于null reject的outerjoin Simplification,见2.1)
- selection算子下推
- leftouter join 或 rightouter join 转 inner join
- join reorder
- 提出广义outerjoin算法(Generalized Outerjoin),
- join reorder变换的恒等式
这里重点介绍Outerjoin Simplification(outerjoin 化简)算法,因为这个算法至今仍在主流数据库优化器中使用。
简单说明join reorder算法(Generalized Outerjoin),GOJ。因为这个算法在使用中存在很多局限性,例如仅适用于simple outerjoin,基于query graph进行实现,实现难度大。
对于join reorder算法感兴趣的同学可以阅读《[SIGMOD 13]On the correct and complete enumeration of the core search space》,论文主体算法已经应用于TiDB、PolarDB、CockroachDB等多款主流数据库中。
[VLDB 2006]Analysis of Two Existing and One New Dynamic Programming--论文学习
论文描述了现有文献中的两种构造join order tree的动态规划算法的方法,DPSize算法、DPsub算法,通过分析和实验表明,这两种算法对于不同的query graph表现出非常不同的效果。更具体地说,对于chain (链型)Join graph查询,DPsize优于DPsub,对于clique(集团型)Join graph查询,DPsub优于DPsize。另外,这两种算法都不能很好的处理star(星型)查询。为解决这些问题,论文提出了一种优于DPSize和DPsub的算法,即DPCpp算法,该算法适用于所有类型的query graph。
CRDB主要实现了DPSube算法,其最初的来源为DPsub算法。
[SIGMOD 13]On the correct and complete enumeration of the core search space--学习
本文针对多表join,基于交换律、结合律、左结合律、右结合律,进行等价转换,产生正确且完整的plan集合(core search space),论文主体算法已经应用于TiDB、PolarDB、CockroachDB等多款主流数据库中。
再读[SIGMOD 13]On the correct and complete enumeration of the core search space
本文针对当前主流两种基于动态规划的plan生成器(DB-based plan generator)算法,即NEL/EEL方法算法、SES/TES方法等会在Join Reorder中产生无效plans的问题,论文提出了三种Join Reorder过程中的冲突检测算法(CD-A、CD-B、CD-C),其中CD-C最为完备,能够用于生成完整的core search space(搜索空间),即根据初始的plan,基于Join Reorder算法,生成所有合法的候选plans的集合。
[ACM,2013]HyperLogLog in Practice Algorithmic Engineering of a State of The Art 学习笔记
基数估计(Cardinality Estimation),也称为 count-distinct problem,是为了估算在一批数据中,它的不重复元素的个数,distinct value(DV),具有广泛的应用前景,在数据库系统中尤为重要。虽然基数可以很容易地使用基数中的线性差值来计算,但对于许多应用程序,这是完全不切实际的,并且消耗大量内存。因此,许多近似基数而使用较少资源的算法已经被开发出来。这些算法在网络监控系统、数据挖掘应用程序以及数据库系统中发挥着重要的作用,HyperLogLog算法就是其中之一。
目前,HyperLogLog算法已经应用于Redis、PolarDB PostgreSQL、OpenGauss、CockroachDB、AnalyticDB for PostgreSQL、PostgreSQL、Spark、Flink、Presto等。
在本文中,作者提出了对该算法的一系列改进,以减少了其内存需求,并显著提高了其对一个重要的基数范围的精度。作者已经为谷歌的一个系统实现了这个新提出的算法,并对其进行了经验评估,并与改进前的HyperLogLog算法进行了比较。与改进前的HyperLogLog一样,作者改进的算法可以完美地并行化执行,并在single-pass中完了基数估计的计算。
[University of Waterloo 2000]Exploiting Functional Dependence in Query Optimization
ANSI SQL关系模型中已经包括函数依赖分析,但函数依赖分析具有复杂性,因为存在如下情况:
- 空值
- 三值逻辑(three-valued logic),即TRUE、FALSE、UNKNOWN
- outer joins
- 重复的rows
那么如何简化函数依赖分析,并充分利用函数依赖分析进行查询优化呢?
本文是滑铁卢大学2000年的一篇博士论文,主要解决了这方面的问题。论文虽然有些老,但学完之后还是感觉收益匪浅,特别是通过研读本文提供的函数依赖定义、定理、推理等,有助于理解函数依赖在如下SQL优化中的作用:
- selectivity estimation
- estimation of (intermediate) result sizes
- order optimization(in particular sort avoidance)
- cost estimation
- various problems in the area of semantic query optimization
[SIGMOD 1996]Fundamental Techniques for Order Optimization 论文学习
这是DB2 96年的一篇关于join中order(排序)优化论文,提出了具体的优化方法,并概述了DB2的工程实现。这篇论文虽然比较老,但至今仍有很大的指导作用。
在数据库优化器中,排序是一个非常消耗资源的算子,如果能够利用数据中的索引或排序的属性,降低对排序算子的使用,可以大幅提升SQL执行效率。具体来说,在Group By、Order By、Distinct子句中,父节点都会对子节点提出 Interesting Order ,优化器如果能够利用底层已有的序(例如,主键、索引),满足 Interesting Order,就不需要对底层扫描的行做排序,还可以消除 ORDER BY。
论文提出了一种在join中下推sort算子的方法,以减少按照columns对数据的排序,基于谓词、索引、主键信息,在等效情况下,消除排序算子。
为了便于对论文的理解,这里对Interesting Order、Physical Property进行解释。
- Interesting Order:(也许叫Interesting Property更合适,因为多数Interesting的都是排序属性。)由父节点传给子节点,要求其返回满足特定Physical Property的最优计划,例如升序、降序。另一个能够解释“Interesting Order”名称的是Join Order。在多表互Join时,表的Join顺序(Join Order)排列组合数量巨大,影响查询性能;父节点需选择哪些Join Order应被进一步探索(Join Enumeration)。它们成了“Interesting Order”。
- Physical Property:Operator返回的结果带有的属性,最典型的例子是排序与否;还例如结果是否已计算Hash;结果在单服务器上,还是分散在多服务器(需要额外GatherMerge)。
在开始做CBO之前,优化器会top-down的遍历QGM,针对不同算子可能的有序性需求(join/group by/distinct/order by),建立算子的interesting order,这个过程称为对QGM的order scan。
[IEEE Data engineering Bulletin 1995]The Cascades Framework for Query Optimization论文阅读,CRDB采用了Cascade架构。
[SIGMOD 2014]Orca: A Modular Query Optimizer Architecture for Big Data 论文阅读,Cascade架构实现类似ORCA。
[SIGMOD 2017]Spanner Becoming a SQL System--学习笔记
Spanner是一个面向全球的分布式DBMS,为谷歌数百项关键服务提供数据支撑。谷歌在OSDI‘12上发表了第一篇Spanner的论文,那个时候的Spanner可以理解分布式KV数据库,支持动态扩缩容、自动分区、多版本、全球部署、基于Paxos的多副本机制、支持外部一致性的分布式事务(SSI),详见[OSDI '12]Spanner Google’s Globally-Distributed Database。本文讲的是Spanner后续实现的分布式SQL引擎,包括分布式查询执行、临时故障时查询重启、如果根据查询数据的范围将请求路由到数据所在的range(数据分片)、索引的查询机制以及在存储方面的优化。
目前,两个著名的分布式NewSQL数据库tidb和cockroach,就是inspire by Spanner 和 F1。
CRDB向量化执行引擎inspire by MonetDB-X100,但未使用SIMD。
[CIDR 2005]MonetDB-X100 Hyper-Pipelining Query Execution--学习笔记
Balancing Vectorized Query Execution with Bandwidth-Optimized Storage-第四章MonetDB/X100 overview--学习笔记
Balancing Vectorized Query Execution with Bandwidth-Optimized Storage-第五章MonetDB/X100向量化执行引擎
Hyper提出了很多经典算法,但未开源,不过这些算法基本都在DuckDB中实现了。
Unnesting Arbitrary Queries--Hyper去相关子查询论文学习
SQL 99中允许子查询出现在SELECT、FROM和WHERE子句中,从用户使用的角度看,嵌套子查询能够极大地简化复杂查询的形式。但是,在相关子查询中,优化器不加处理,直接传递给执行器计算,其算法复杂度为N方,数据量大的情况下,性能极差。paper提出来了一种去相关子查询的通用且高效算法。
[BTW 2017]The Complete Story of Joins (in HyPer)--HyPer去相关子查询论文学习
这篇论文是《[BTW 2015]Unnesting Arbitrary Queries》的延续,在去相关子查询方面,提出了两个新的Join扩展算子mark-join和single-join,并给出了逻辑上的等价变换规则,物理上的实现算法。
[SIGMOD 2008]Dynamic Programming Strikes Back--读书笔记
DPCCP算法与DPsize和DPsub算法相比优势在于能够高效获取csg-cmp-pairs:
- DPCCP算法
- 连通子图,在query graph中,依次以base tables为种子,步长为1,采用广度优先的方法,对每个种子节点求邻近节点集合,邻近节点的编号必须大于当前节点,这样保证去重,然后基于种子节点和第1级邻近节点集合中的所有非空子集构成种子节点步长为1的所有连通子图,然后对于其中的每个连通子图,再采用类似的方法,步长为1,扩展获得下一级所有的连通子图,以此类推,就可以获取query graph中的所有连通子图
- 连通子图的补图,对于任意的连通子图,以其邻居节点集合中的每个节点为种子节点,采用了和连通子图扩展相似的方式,获取所有的连通子图,其中,扩展时要排除掉原连通子图,并且仅选择比种子节点编号大的节点
- DPCCP通过上述方法,直接获取了csg-cmp-pairs,高效先进
- DPsize和DPsub
- 采用了枚举方式,获取节点集合对,(S1,S2),再判断S1和S2各自是否是连通的,是否存在交集,S1和S2之间是否连通,这样才能得到csg-cmp-pairs,效率要低
DPCCP算法存在如下两个缺陷,使其不能直接应用于数据库实践中,可以理解为是一种学术性的创新。
- 仅能处理inner join,不支持full join,left join,right join,semi join,anti join等
- 仅能处理简单的join谓词,即join的left input或right input仅包含1个base table,无法处理这种join两个是多个base tables的复杂join谓词,t1.a=t2.b + t3.d
本文是DPCCP算法的延续,开发了一种新的算法DPhyp,能够保留DPCCP在寻找csg-cmp-pairs方面的优势,并解决DPCCP的2个缺陷。
MySQL 8.0中已经实现了DPhyp算法。CockroachDB采用了DPSube算法查找best join order,但将DPhyp列为了TODO。
[VLDB 2015]How Good Are Query Optimizers, Really
论文的作者是大名鼎鼎的CWI实验室Peter Boncz教授、慕尼黑工业大学数据库研究组长Thomas Neumann教授和Alfons Kemper博士,其中,Peter Boncz教授是MonetDB的创始人之一,Thomas Neumann是HyPer的创始人之一。
论文认为,Join orders对查询的性能非常重要。优化器中,cardinality estimator(基数估计)组件、cost model(代价模型)、 plan enumeration(plan的枚举技术)是查找好的Join order的核心组件。论文设计并实施了Join Order Benchmark (JOB),即Join Order基准测试,实验结果表明:
- cardinality estimation(基数估计)组件:往往产生较大的误差
- cost model(代价模型):其对性能的影响要比cardinality estimator(基数估计)小的多
- plan enumeration(plan的枚举技术):对比了穷举动态规划和启发式算法,发现在次优的基数估计情况下,穷举方法能够改善查询性能
最终,论文得出结论,过度依赖cardinality estimation(基数估计)组件、cost model(代价模型)、plan enumeration(plan的枚举技术),不能得到让人满意的性能。
[VLDB 2011]Efficiently Compiling Efficient Query Plans for Modern Hardware --学习笔记
这篇Paper的作者是著名的Thomas Neumann,慕尼黑工业大学(TMU)的数据库研究组组长,HyPer数据库的初始人之一。论文讲述了如何在执行器中,编译执行查询计划,CodeGen概念就是出自这篇论文。如果对PostgreSQL、Opengauss等数据库的JIT技术感兴趣的话,推荐阅读原文。
论文认为,随着内存硬件的进步,查询性能越来越取决于查询处理本身的原始CPU成本。经典的火山迭代器模型虽然技术非常简单和灵活,但由于缺乏局部性(locality)和频繁的指令错误预测,在现代cpu上的性能较差。过去已经提出了一些技术,如面向批处理的处理或向量化tuples处理策略来改善这种情况,但即使是这些技术也经常被hand-written计划执行。
这篇论文提出了一种新的编译策略,它使用LLVM编译器框架将查询转换为紧凑而高效的机器代码。通过针对良好的代码和数据局部性和可预测的分支布局,生成的代码经常可以与手写的C++代码相媲美。将这些技术已经集成到HyPer数据库系统中,获得了很好的查询性能,而只需要增加适度的编译时间。
[SIGMOD 2018]Apache Calcite 论文学习笔记
Apache Calcite是一个基础的软件框架,提供SQL 解析、查询优化、数据虚拟化、数据联合查询 和 物化视图重写等功能,目前已经应用于多款开源数据库或大数据处理系统中,例如
- Apache Hive,Apache Storm,Apache Flink,Druid 和 MapD
- Polar-X、Doris、StarRocks、SelectDB
Calcite框架组成如下:
- 查询优化器,内置几百种优化规则,模块化且可扩展
- 查询处理器,支持多种查询语言
- 适配器模式的体系结构,支持多种异构数据模型(关系结构格式、半结构化格式、流格式、地理信息格式)
Calcite框架具有灵活性、可嵌入性、可扩展性等特点,因此,对于涉及多源异构类型的大数据框架来说,很具吸引力。Apache Calcite项目非常活跃,持续支持新型数据源、查询语言、查询处理以及查询优化方法。
[ICDE 1993]The Volcano Optimizer Generator- Extensibility and Efficient Search (Calcite优化器架构)
Volcano模型旨在解决扩展和性能问题。EXODUS是同一个作者在Volcano的一个优化器设计的版本,EXODUS虽然已经证明了优化器生成器范式的可行性和有效性,但很难构建高效的、满足生产环境质量的优化器。Volcano也是在EXODUS的基础之上优化而来。Volvano在EXODUS上面的做的一些优化: 前者(EXODUS)没有区分逻辑表达式和物理表达式,也没有物理Properties的概念,没有一个通用的Cost函数等等。Volcano优化器要满足如下目标:
- 这个新的优化器生成器必须能够使用Volcano Executor,也可以在其他项目中作为独立的工具
- 必须更加高效,比较低的时间消耗和内存消耗
- 必须提供有效的,高效的,和可扩展的物理属性支持,如sort order、compression
- 必须允许使用启发式和数据模型语义来指导搜索并删除搜索空间中无用的部分(剪枝)
- 它必须支持灵活的代价模型,对于查询中的子项能够产生动态查询计划
[SIGMOD 2014]Orca: A Modular Query Optimizer Architecture for Big Data 论文阅读
?Orca是Pivotal公司基于Cascade优化器框架开发的SQL优化器服务,以独立的Service形态单独存在,并不依附于特定的数据库产品,对外是标准化的接口和协议,调用者通过标准化的输入,由Orca负责根据输入指定SQL执行计划,由调用者将这个基于Orca的SQL执行计划转换成自身数据库的SQL执行计划,这样理论上可以被集成到任何数据库系统中。已经应用于Greenplum和基于Hadoop的HAWQ中。是Volcano/Cascades的论文思想的一个业界著名的工程化实现。
[IEEE Data engineering Bulletin 1995]The Cascades Framework for Query Optimization论文阅读,支持Cascade架构
[SIGMOD 1979]Access Path Selection in a Relational Database Management System 论文阅读,支持System R架构
[VLDB 2016]The MemSQL Query Optimizer,HTAP优化器论文阅读
当前主流优化器有2种,System R(bottom-up)和Volcano/Cascades(top-down),二者各有千秋。 但对于MemSQL来说,皆无法满足需求。
这是因为,MemSQL是一个高性能、分布式HTAP数据库,需要解决OLAP实时负载分析问题,要求SQL优化时间非常有限,现有优化器框架不能满足这个需求,集成已有优化器框架还意味着继承框架的所有缺点和集成挑战。因此,MemSQL从头开始构建,采用了创新的工程,如内存优化锁(lock - free)和能够运行实时流分析的列存储引擎(columnstore engine),开发了一个功能丰富的查询优化器,能够跨各种复杂的企业工作负载生成高质量的查询执行计划。
[CIDR 2005]MonetDB-X100 Hyper-Pipelining Query Execution--学习笔记,简介见上文
Balancing Vectorized Query Execution with Bandwidth-Optimized Storage-第四章MonetDB/X100 overview--学习笔记,简介见上文
Balancing Vectorized Query Execution with Bandwidth-Optimized Storage-第五章MonetDB/X100向量化执行引擎,简介见上文
[DaMoN 2011]Vectorization vs. Compilation in Query Execution--学习笔记,简介见上文
在关系数据库中,查询执行一般有三种策略,解释型执行、编译执行和向量化执行。在OLAP领域,编译执行和向量化执行要优于解释执行的方式。但编译执行和向量化执行哪种更佳?如何基于现代CPU,为向量化执行引擎配置好编译执行的策略,获取最佳性能?围绕这个问题,这篇论文就行了研究分析。作者针对Project、Select、Hash join算子深入调研分析了VectorWise(MonetDB X100的商业化版本)数据库的向量化执行引擎和编译策略。调研发现
- 对于block-wise 查询执行引擎来说,最好使用编译执行的方式
- 找到了三种场景下,“loop-compilation”策略不如向量化执行引擎
- 如果能较好的将编译执行和向量化执行结合,可以获取更好的性能
- either by incorporating vectorized execution principles into compiled query plans
- using query compilation to create building blocks for vectorized processing
[DBTest 2012]Testing the Accuracy of Query Optimizers论文阅读
查询优化器的准确性与数据库系统性能及其操作成本密切相关:优化器的成本模型越准确,得到的执行计划就越好。数据库应用程序程序员和其他从业者长期以来提供了一些轶事证据,表明数据库系统在优化器的质量方面存在很大差异,但迄今为止,数据库用户还没有正式的方法来评估或反驳这种说法。
在本文中,我们开发了一个TAQO 框架来量化给定工作负载下优化器的准确性。我们利用优化器公开开关或hint,让用户控制查询计划,并生成除默认计划之外的计划。使用这些实现,我们为每个测试用例强制生成多个替代计划,记录所有替代计划的执行时间,并根据它们的有效成本对执行计划进行排序。我们将这个排名与估计成本的排名进行比较,并为优化器的准确性计算一个分数。
我们给出了对几个主要商业数据库系统进行匿名比较的初步结果,表明系统之间实际上存在实质性差异。我们还建议将这些知识纳入商用数据库开发过程。
[CIKM 2016]OptMark- A Toolkit for Benchmarking Query Optimizers--优化器评价论文学习
如何评估数据库优化器的质量,这个问题非常有挑战性。目前,现有数据库的benchmarks测试(如TPC benchmarks)是对整体的query的性能评估,并不是针对优化器。这篇论文描述了OptMark,一个用于评估优化器质量的toolkit,可惜没有开源。论文从Effectiveness(有效性) 和Efficiency(效率)两个维度,评价优化器的质量,并给出了具体的评价公式。
[SIGMOD '00]Counting, enumerating, and sampling of execution plans in a cost-based query optimizer学习
在对优化器的测试中,一项重要的测试内容是,对比分析优化器选出的plan的执行时间与优化器中其他候选plans的执行时间,进而判断优化器从候选plans中选择较佳的plan的能力,那么问题就来了,如何才能知道优化器中,其他候选plans的执行时间?
这篇论文给出了一个很好的方法,就是在优化器制定query的执行计划过程中,建立好数字和候选plans的对应关系,在SQL语句执行时,用户可以输入数字,指定执行plan。这个技术已经应用到SQL Server的优化器测试验证中了。
由于SQL Server采用了Cascade框架,因此,整个实现是围绕MEMO结构进行的。
[Data Engineering Bulletin '08]Testing SQL Server's Query Optimizer--学习笔记
查询优化本身就很复杂,因此,验证优化器的正确性和有效性是一项非常复杂的工作。正确性是说生成的查询计划对标原sql,能不能保证结果集的正确性;有效性是说,对原sql执行RBO+CBO变换后,得到的执行计划是不是高效的。
这篇论文描述了测试查询优化器时遇到的一些独特问题,概述了验证微软SQL Server的查询优化器的测试技术,给出了优化器测试过程中的成功经验和教训,最后讨论了测试器测试中持续存在的挑战。
论文更多的是从测试工程的角度说明优化器测试问题,以及微软SQL Server是如何测试优化器的,给出的方法相对要宏观一些,或者说更像是一种方向性的指引。很遗憾,可能是出于商业保密的原因,论文并没有公开优化器测试的实现机制。论文[DBTest 2012]Testing the Accuracy of Query Optimizers,给出了优化器测试的数学模型,但没有从系统工程的角度说明如何进行优化器的测试。这两篇论文有很强的互补性,都是很值得学习的。
[SIGMOD 1996]Improved Histograms for Selectivity Estimation of Range Predicates
许多商业数据库会维护直方图,用直方图来概括关系表的内容的特征,以此高效评估结果集大小,以及评估各种查询计划的代价。尽管过去已经提出了几种直方图,但还没有关于直方图的系统研究的论文,还有直方图的选型对效率的影响等。本文中作者提出了一个直方图的分类方法,这个分类能包括现有的直方图,并指出了一些新的直方图的可能性。我们为几个分类维度引入了新的选项,并通过以有效的方式组合这些选项来推导出新的直方图类型。我们还展示了如何使用采样技术来降低直方图构建的成本。最后,我们给出了用于范围谓词选择性估计的直方图类型的实证研究结果,并确定了具有最佳整体性能的直方图类型。
[VLDB 2003]The History of Histograms--学习笔记
直方图的历史悠久而且内容丰富,每一步都有详细的信息。直方图的历史包括
- 不同科学领域的直方图的过程
- 直方图在近似和压缩信息方面的成功经验和失败教训
- 直方图的工业应用
- 以及在各种直方图相关问题上给出的解决方案
在本文中,本着与直方图技术本身的相同精神,我们将直方图的整个历史(包括它们目前预期的“未来历史”)压缩到给定/固定的budget中,主要periods、events和results的最高(个人偏见)兴趣的细节。在一组有限的实验中,发现直方图的历史的压缩形式和完整形式之间的语义距离相对较小!
[VLDB 2009]Preventing Bad Plans by Bounding the Impact of Cardinality Estimation Errors
对于基数估计来说,q-error的指标Iq是一个更有意义的度量指标
- 如果构建的直方图能够保证q-error的阈值,则优化器能够对查询优化结果进行一定程度的保证
- 如果q-error不能满足阈值,代价评估的误差也能够在q^4
论文开发了一种能够最小化Iq的直方图构建算法
- 基于快速迭代的算法构造直方图的单桶
- 采用了多段拟合方式,适用范围更广
- 使用二分法构建直方图的多个桶
- 提供了比其他方法更好的近似值
- 特别是,更稳健,plan的质量是有边界的!
[SIGMOD 2015]Rethinking SIMD Vectorization for In-Memory Databases--学习笔记
论文作者来自哥伦比亚大学和Oracle。论文基于先进的SIMD指令,例如gathers和scatters,提出了一种新的向量化执行引擎,并给出了selection scans、hash tables、partition的向量化实现代码,在这些基础上,实现了sort和join等算子。论文将提出的向量化实现技术与最先进的scalar和vectorized技术进行了对比,通过在Xeon Phi以及主流CPU的实测结果,证实论文提出的技术的高性能。
论文[tpctc 2013]TPC-H Analyzed Hidden Messages and Lessons Learned from an Influential Benchmark更像是查询优化器核心算法的骨架,虽然没有深入描述某个技术,但以TPC-H的query为例,系统且深入的分析了复杂query中提升性能的关键点,并给出了对应的优化思路。
[SIGMOD 2018]How to Architect a Query Compiler, Revisited --学习笔记
为了充分利用现代硬件平台,越来越多的数据库系统将执行计划编译为机器码,例如引入llvm。在学术界,关于构建此类查询编译器的最佳方法,一直存在争论,认为这是一项非常困难的工作,与传统的解释型执行计划相比,需要采用完全不同的实现技术。
论文的目标是引入Futamura projections(二村映射)技术,它从根本上将解释器和编译器联系起来。在这个想法的指导下,作者开发了LB2,一种高级的查询编译期,它的性能与标准TPC-H基准测试上的最佳编译查询引擎相当,有时甚至更好。
从优化器综述论文学习System-R框架和Cascade框架
在数据库中,优化器之所以重要,是因为SQL是一种声明式的语言,只是告诉用户需要什么数据,但获取数据往往有多条路径,路径间代价差异可能会很大,优化器则是负责快速、高效的找出获取数据的最佳执行路径,是数据库的大脑,可谓得优化器者得数据库天下。
论文An Overview of Query Optimization in Relational Systems写于1998年,虽然古老,但切实抓住了70年代以来的优化器的要点,综述了2种优化器框架,System-R(bottom-up)和Cascade(top-down)。
[VLDB,1997]SEEKing the truth about ad hoc join costs--学习笔记
在本文中,作者开发了一个详细的代价模型,可以来预测join算法的性能。作者使用这个代价模型研究每种join方法的最优的缓冲区分配方案。实验结果表明,在模型情况下,性能可以提升400%。
这篇论文细致的去分析了多种Join算法的代价模型,主要是给出了分析的过程,这对于学习数据库代价评估模型非常有帮助,可以知其所以然。否则,只是知道代码里的一系列公式,为什么是这样子,理解的不一定到位。
个人理解:这篇论文的题目中
- “seek the tuth”:其实就是说ad hoc join查询的代价都有哪些,为什么会有这些代价,这些代价在不同的可用内存情况下,是什么表现,因此最终可以给出各种join算法的最优内存评估,这些可以构成资源管理中,不同join算法内存预估的理论基础,研读这方面的实现机制时,可以用来参考
- ad hoc join:即席查询,也就是说一次query执行一次编译并生成执行计划,不会使用查询计划的缓存。即席查询主要用于AP场景,对于跑批业务来说,业务是固定的,很多时候,可以使用plan cache,但对于其中,突然新增的一个sql且仅执行一次,即常规业务外的sql,需要直接编译执行
学习这篇论文花了好多精力,但在理解代价评估模型的原理方面,收益很大。之前也看过一些关于数据库原理、优化器原理以及实现的方面的书籍、论文、技术博文,包括一些数据库的实现,但在代价模型原理方面总有一种总感觉不够透彻,这篇论文个人感觉还是很深刻的。


